AI compute used to be an engineering line item buried inside cloud spend.
In 2026, for any startup whose product calls an LLM, it is a forecast line item that directly determines unit economics, gross margin, runway, and fundraising timelines.
Most advice about AI costs focuses on optimization tactics:
- use smaller models
- reduce token usage
- cache responses
- buy fewer API calls
Those tactics matter. But they miss the bigger question: how do you forecast AI compute costs as your business grows?
Founders already forecast payroll, cloud infrastructure, software subscriptions, and revenue. AI compute should be treated the same way: as a recurring operating expense that belongs inside the AI cash flow forecast.
The companies that win over the next five years will not necessarily be the ones with the most advanced models. They will be the ones that understand the economics of those models.
The New Forecast Line Item
Before 2024, most startups treated infrastructure costs as relatively predictable overhead. You paid for cloud servers, databases, storage, and networking. Costs increased gradually with scale.
AI changed that. Every user interaction can now create a direct variable cost. Every prompt sent to an LLM has an associated inference cost.
Every agent workflow may trigger:
- multiple model calls
- retrieval operations
- embedding generation
- tool execution
- external API requests
The result is a cost structure that behaves very differently from traditional SaaS. A customer generating 10 times more AI activity may generate 10 times more compute spend. That makes forecasting AI compute costs for founders in 2026 fundamentally different from forecasting traditional cloud infrastructure.
This challenge is becoming increasingly important as AI adoption grows. Goldman Sachs Research projects that AI token consumption will multiply roughly 24 times by 2030, to about 120 quadrillion tokens a month, as agent adoption scales. Per-token prices keep falling. Total consumption is growing faster.
For founders, this means AI compute is no longer simply a technical concern. It is a financial planning concern.
The Inference Cost Paradox
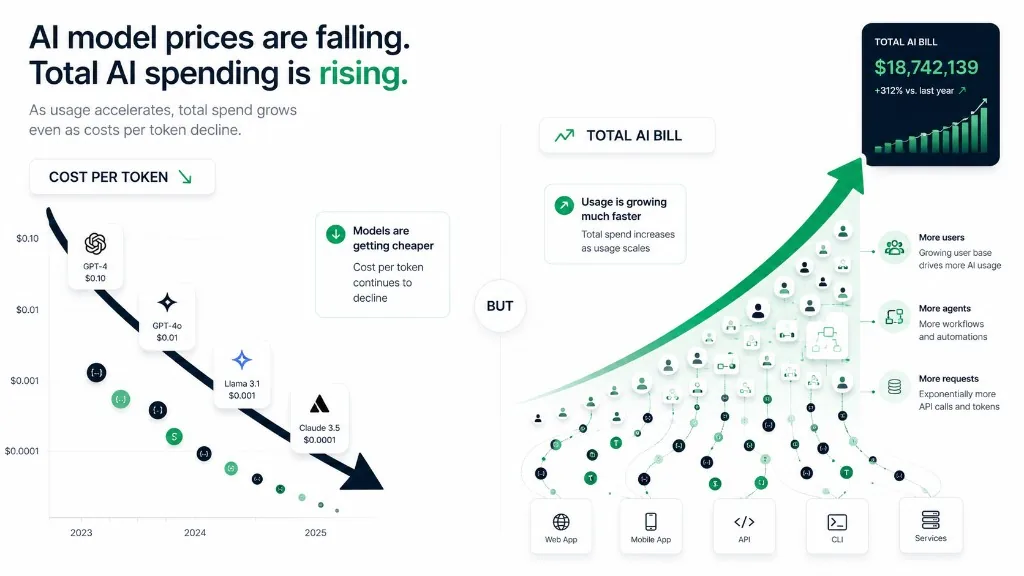
One of the most misunderstood trends in AI economics is what many operators now call the inference cost paradox.
Model prices keep falling. Total AI bills keep rising.
At first glance, that seems impossible. Historically, per-token inference costs have declined significantly year after year. New models are more efficient, competition is increasing, and providers continue to optimize infrastructure.
Yet enterprise AI spending continues to rise. The same Goldman Sachs analysis expects enterprise agents alone to consume 56 quadrillion tokens a month by 2030, with global daily AI query volume growing from roughly 5 billion in 2025 to 23 billion. Inference dominates enterprise AI budgets because usage is growing faster than costs are falling.
Imagine a startup that launched an AI-powered fraud analysis agent:
- late 2025: 50 users, $5,000/month compute spend
- six months later: 500 users, $15,000/month compute spend
The cost per request fell. The total bill increased. This is the same phenomenon that transformed cloud computing, but at a much faster pace.
Founders who assume falling API prices will automatically improve margins often underestimate how quickly token consumption can scale.
The question is no longer "will model costs fall?" The question is:
"Will model costs fall faster than usage grows?" That is the number that belongs in your AI compute cost forecast.
AI Margins vs Traditional SaaS Margins
Traditional SaaS companies benefited from an extraordinary economic advantage. Once software was built, the cost of serving one additional user was relatively low. This is why many SaaS businesses achieved gross margins between 80% and 90%.
AI-first companies operate differently. Every customer interaction may generate real-time compute expenses. The result is a new margin profile.
Andreessen Horowitz flagged this pattern as early as 2020: many AI-native products operate in the 50% to 60% gross margin range, significantly below traditional SaaS benchmarks, because every request carries real compute cost.
Investors are increasingly evaluating startups through this lens. A company growing rapidly but spending an increasing percentage of revenue on inference may be viewed as less attractive than a slower-growing company with healthier economics.
This is why AI startup unit economics have become a major topic in venture capital discussions throughout 2026. Growth alone is no longer enough. Margins matter.
How to Model AI Compute as a Variable Cost
The biggest forecasting mistake founders make is treating AI spend as a fixed monthly expense. It is not. AI compute behaves more like payment processing fees: usage drives cost.
The most practical AI compute cost forecast model is to model compute costs at three levels. Treat tokens as a consumable input with a unit price, the same way finance teams model any other variable COGS line.
Per Query
Start with: average tokens per request × API price. This creates a baseline AI cost per query.
For example:
- 8,000 tokens per workflow
- known API pricing
- estimated request volume
This gives a forecastable cost per transaction.
Per User
Many founders prefer forecasting AI cost per user.
Example:
- 250 active users
- 1.5 million tokens per user per month
- current API pricing
This creates an estimated monthly compute budget. This approach is particularly useful when you forecast AI costs as users grow alongside customer acquisition.
Per Feature
Not all AI features cost the same. A chatbot might trigger one model call. An AI agent might trigger planning, tool selection, retrieval, multiple reasoning steps, and final response generation.
The architecture itself determines the forecast curve. This is why AI agent costs often grow faster than expected. Founders should forecast AI compute at the feature level whenever possible.
Include Retrieval and Embedding Costs
Many forecasts underestimate true AI operating costs. Inference is only part of the equation.
Modern AI systems often include:
- vector databases
- retrieval pipelines
- embedding generation
- search infrastructure
- tool execution layers
These costs can become meaningful as usage scales. A realistic AI inference costs SaaS forecasting model includes both direct inference spend and supporting AI infrastructure costs. Ignoring the second category often creates surprises later.
The Inference-to-Revenue Ratio
One of the most useful metrics emerging in AI SaaS is the inference-to-revenue ratio.
The formula is simple: inference costs ÷ revenue.
For example:
- monthly revenue: $100,000
- monthly AI compute spend: $8,000
- inference-to-revenue ratio: 8%
This metric provides a quick way to evaluate unit economics. A practical benchmark we use at Zensus: keep inference spend below 10% of revenue for a chat-heavy product. Above that line, compute is no longer a rounding error; it is a first-class cost driver that belongs in the forecast.
Above that level, scaling becomes more challenging. Margins compress. Runway shrinks. Fundraising conversations become harder. Below that level, startups typically have more flexibility to invest in growth while maintaining sustainable economics.
For founders, this may become one of the most important AI cost benchmarks to monitor.
How AI Compute Costs Affect Runway
Most founders think about runway in terms of payroll, marketing, office expenses, and infrastructure. AI compute now belongs on that list.
Imagine two startups generating identical revenue:
- Company A spends $5,000/month on inference
- Company B spends $50,000/month on inference
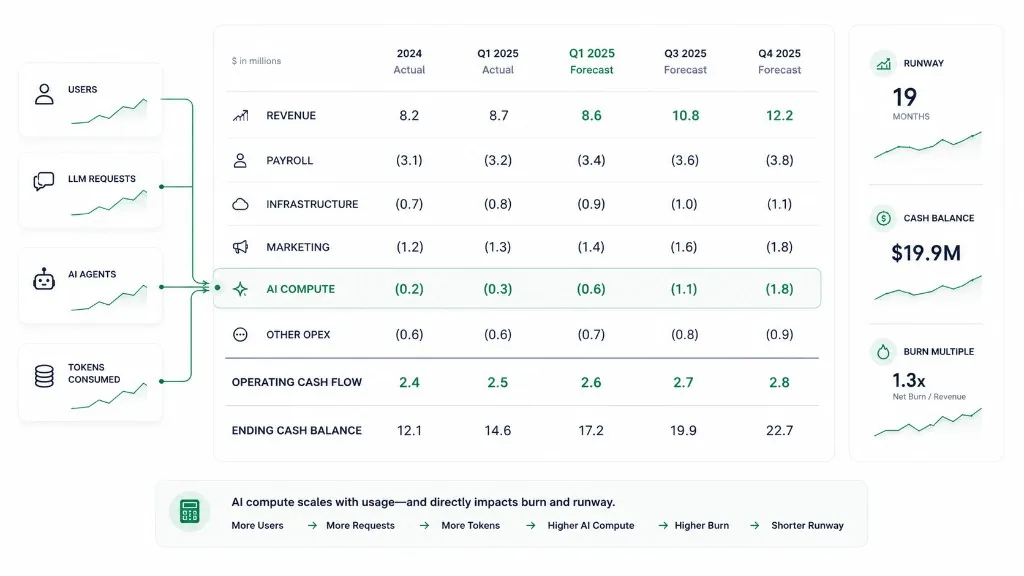
Both businesses may appear similar on the surface. Their cash burn profiles are dramatically different. This is why AI compute should be modeled directly within the cash flow forecast, including a rolling 13-week view if you run weekly liquidity reviews.
At Zensus, we think about AI spend the same way finance teams think about payroll. It is not simply a technology expense. It is a recurring operating cost that affects runway, hiring plans, and fundraising timelines.
When founders run forecast scenarios inside Zensus, compute costs become part of the same financial model as revenue growth, hiring, and operating expenses.
What to Plan For
Many startups assume API prices will continue falling forever. That assumption may prove dangerous. Competition has driven rapid pricing declines across the AI ecosystem, but sustainable economics eventually matter.
Conservative financial models should stress-test scenarios where AI pricing stabilizes or even increases. A useful planning exercise is to model three cases:
Base Case
Current pricing remains stable.
Upside Case
Pricing declines significantly. Margins improve.
Downside Case
Pricing increases by 30% to 50%. Usage grows faster than expected. Compute spend expands materially.
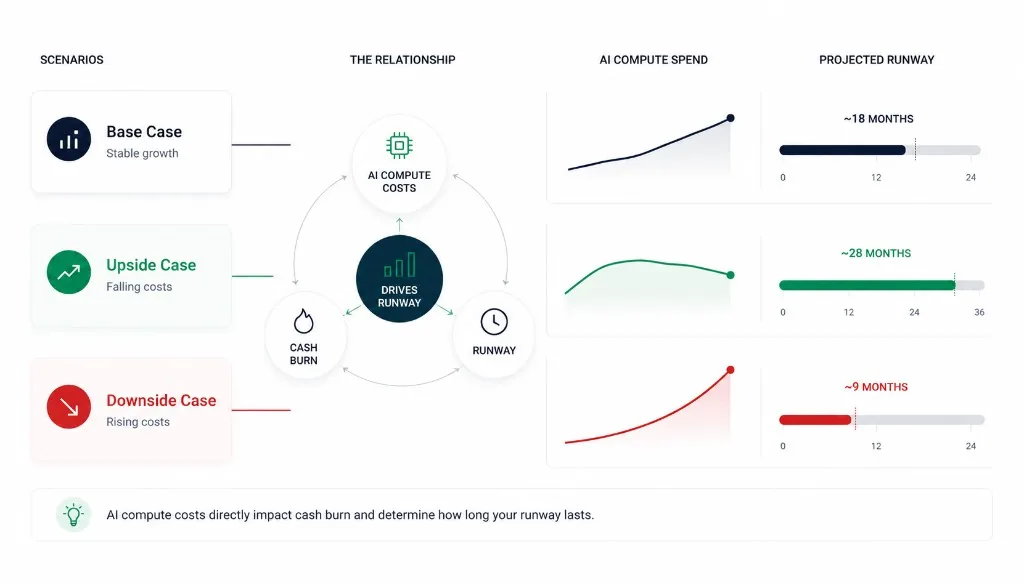
The purpose of forecasting is not prediction. It is preparation. The best founders understand how their business performs across all three scenarios, and can iterate those cases in one place instead of copying three spreadsheet tabs.
Architecture Determines Economics
Many discussions about AI costs focus entirely on model selection. In practice, architecture often matters more.
Two companies using the same model can have radically different cost structures. A poorly designed workflow may make unnecessary model calls, re-run retrieval steps, duplicate context processing, and increase token usage dramatically. A well-designed workflow minimizes expensive operations.
This is one reason Zensus intentionally uses a cost-efficient architecture for its runway agent, the same typed, scoped approach we describe in our guide on MCP vs CLI for finance teams. Instead of repeatedly querying large contexts, the system relies on structured financial snapshots, typed integrations, scoped tools, and purpose-built workflows. The result is lower inference cost per request and more predictable scaling economics.
The same principle applies to every founder building AI products. The architecture of your AI features determines your future compute bill.
How Zensus Helps Founders Model AI Costs
Most forecasting systems were designed before AI became a major operating expense. As a result, founders often track AI costs separately from the rest of the business. That creates blind spots.
Zensus helps teams forecast AI compute expenses, payroll, revenue, hiring plans, infrastructure costs, and runway inside a single financial model on the features page. Bank, accounting, and subscription data connect via Plaid, QuickBooks, and HubSpot; see how it works for the connect-to-forecast flow.
Founders can then answer questions such as:
- what happens if AI usage doubles?
- how much runway do we lose if compute costs rise 40%?
- can we afford another engineer?
- how does an AI feature launch affect burn?
These are not engineering questions. They are financial planning questions, and the same model supports weekly drill-down, scenario planning, and Slack alerts when your 30-day projection crosses a threshold you set.
Final Thoughts
AI compute is becoming one of the most important variable costs in modern software businesses. The founders who treat it as a forecast line item will make better decisions than those who treat it as an unpredictable engineering expense.
The goal is not minimizing tokens. The goal is understanding future spend.
Just as startups forecast revenue, payroll, and infrastructure, they should forecast AI compute costs. Because in 2026, AI compute is no longer just a cloud expense. It is part of the business model itself. For the broader forecasting framework (methods, horizons, and accuracy practices), see our guide on cash flow forecasting.